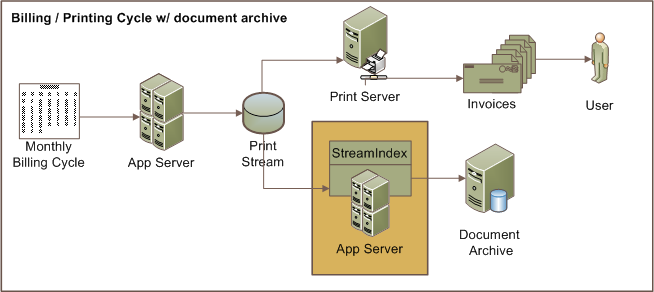
StreamIndex
StreamINDEX parses document, report and print stream data for index information and then returns individual documents or document offsets so they can be archived or the documents stored in a database so that it can be retrieved quickly and easily.
The index information stored with the document is used to facilitate fast and efficient retrieval of the print stream data. Storing document data in the database allows system architects to use standard SQL to access their document data.
Application Architecture
AFP Flow
Print stream data was originally created to send large spool files to high speed, high capacity printers for printing. Print stream print specifications allow for text rotation, font mappings, page overlays, embedded graphics and much more so that printed documents can become very sophisticated in their appearance. As the Internet has gained in popularity, so too has the demand for information online. Many businesses want to provide added value to the customer while at the same time reducing their own operating costs. One way to provide value and lower costs is by providing customers the ability to choose to receive bills, statements, and other documents via the Internet. Since company’s already have a huge sunk cost in providing the paper bill, StreamIndex leverages that sunk cost by using the print data stream as input, mining the key data, and storing the print data in a manner that will facilitate the fast and efficient retrieval of that data.
